Data Science Methodology

Data Science Methodology is a structured approach that guides data scientists and solving complex problems and making data-driven decisions.
Course Objective
Demonstrate the understanding of data science methodology, CRISP-DM
In the end project, I want to showcase and able to describe how data scientists apply structured approach to solve business problems.
Final Project: Data Science Methodology
Instructions
First, I'll pretend to be both the client and the data scientist to come up with a problem about Credit Card Fraud. This will help me show I understand the Business Understanding stage.
Then, as a data scientist, I'll talk about how I'd use data science methods at each step to deal with the Credit Card Fraud problem I've picked out.
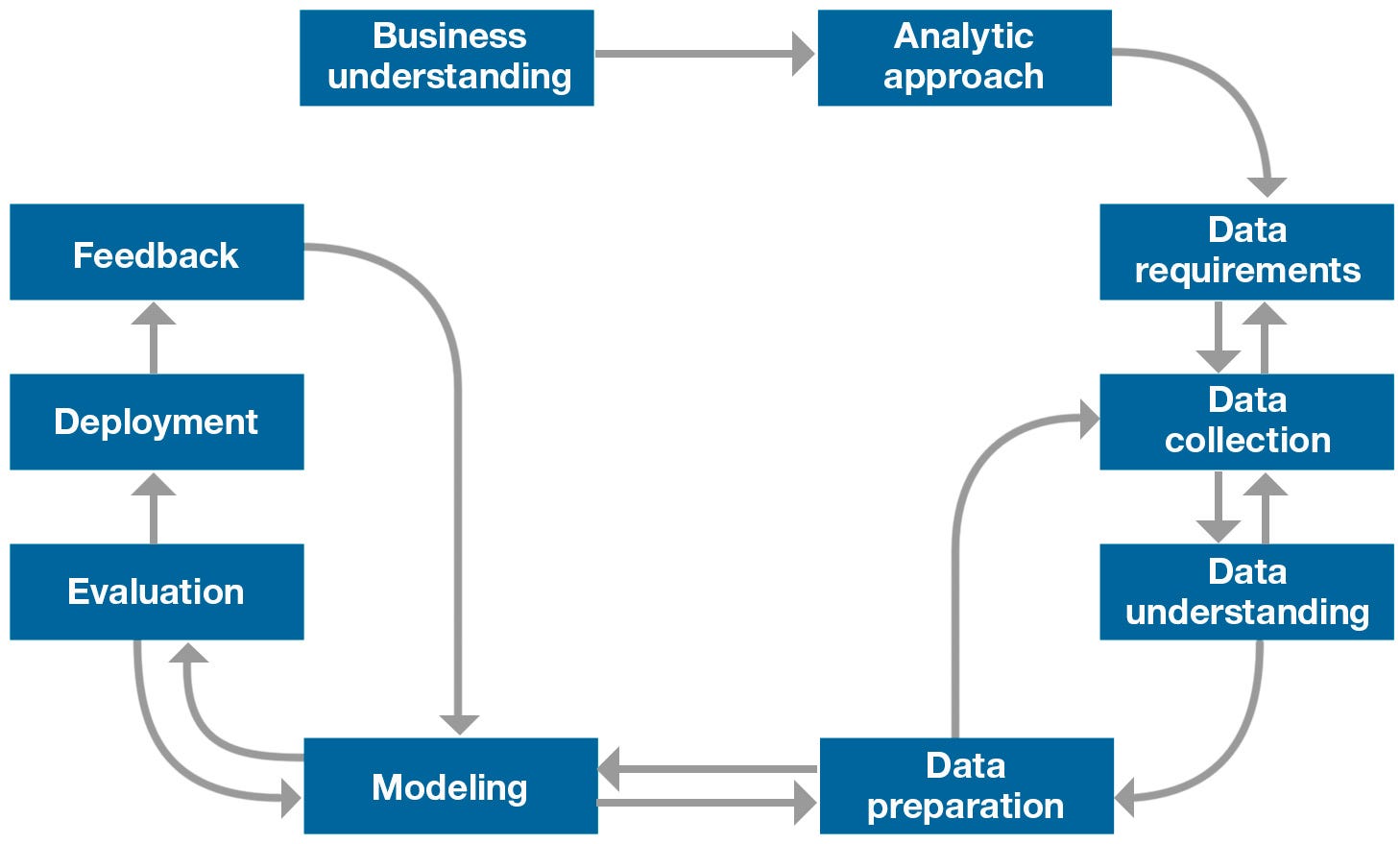
CRISP-DM, which stands for Cross-Industry Standard Process for Data Mining, is an industry-proven way to guide your data mining efforts. CRISP-DM is an iterative data mining mode and is a comprehensive methodology for data mining projects which provides a structured approach to guide data-driven decision making.
I will use the IBM Data Science Methodology Steps as reference and guide on how I will solve and answer the problems per stage. I will proceed as follows:
Business Understanding

Problem Description:
Fraudulent credit cards have specific patterns, attributes and characteristics that serve as strong indicators.
Turn it into a question.
What features or characteristics of credit card transactions are most indicative of fraud?
The goal is to develop a predictive model that can effectively predict between legitimate and illegitimate transactions. This can be done by identifying certain fraudulent features.
The objective is to discern those features (transaction amount, location, time, frequency, etc.) associated with fraudulent activities by analyzing transactional data.
Analytic Approach

Pattern
Identify patterns in credit card transaction data that may distinguish between legitimate and fraudulent transactions.
Explore temporal patterns, transaction amounts, geographical locations, merchant categories, and customer demographics to uncover potential fraud indicators.
Approach
Employ anomaly detection techniques to identify unusual patterns or outliers in the transaction data.
Use clustering algorithms to group similar transactions together and detect any clusters associated with fraudulent activity.
Question Types
Descriptive: Identify any trends or anomalies that may indicate fraudulent activity.
Predictive: Predict the likelihood of future fraudulent transactions based on historical data and learned patterns.
Machine Learning
Apply machine learning algorithms such as logistic regression, decision trees, random forests, support vector machines, or neural networks to detect patterns and classify transactions.
Data Requirement

Define the data requirements (such as amount, time, location), customer information (such as account history, demographics), and additional variables (such as merchant category codes, transaction types). The institution evaluates existing data sources.
Data Collection
Collaborate with different payment processors to obtain transaction data from merchants and online platforms. Some payment merchants may not share data due to privacy conerns or technical limitations. Strategies can be devised to address these gaps, such as imputing missing values or adjusting the analysis to focus on available data sources.
Data Integration
Collect the transaction data using specific standardized format and schema. Develop ETL (extract, transform, load) processes to extract data and standarardized data formats. Clean the data. Identify and remove duplicates, resolve inconsistencies in formats and do validation to ensure data integrity.
Data Understandning

Data Analysts conducts data analysis on the gathered data sets to understand patterns and trends related to credit card transacrions. Use summary statistics and visualize transaction distributions from time, location and the other elements. They can identify potential outliers from the analysis that may indicate fraud.
Data Preparation
The Data Analysts can now begin for the next stage, Data Preparation, by removing the outliers, imputing missing values, etc. The data is transformed into a format suitable for machine learning model training. This ensures that the quality and performance of the data will give precise and reliable outcomes.
Data Modeling
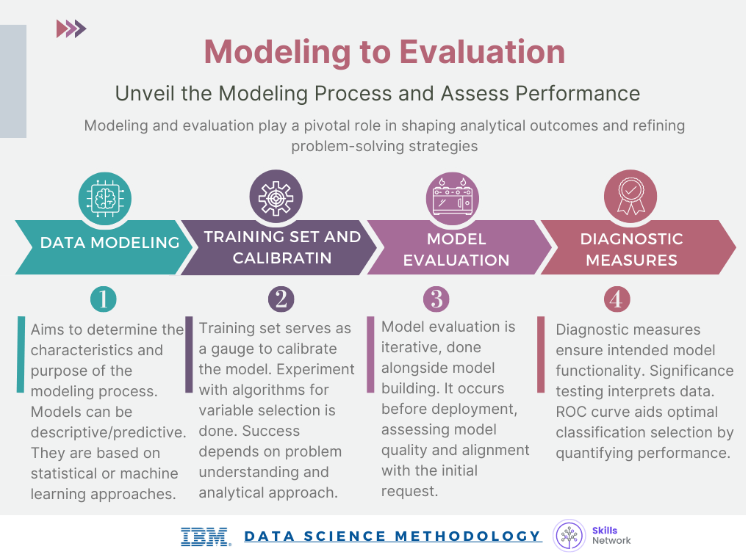
The client and data scientists have decided to develop a predictive model. They also decided to use a machine learning approach to analyze data and identify patterns indicative of fraudulent activities and distiguish the difference between legitamate patterns.
The data scientists experiment with various machince learing alorithms (logistic regression, decision trees, and random forests) to select the best performing model.
Model Evaluation
Data Scientists can now conduct diagnostic measures to ensure the performance and functionality of the final model.
Iterative Process - The model is continously refined and paramters are adjusted based from the previous evaluation results to improve model quality and performance. Here, diagnostic measures and significane testing are also done. This process is done iteratively until the model can effectively mitigate risks associated with fraudulent transactions.
ROC Curve Analysis - Data scientists analyze the receiver operating characteristic (ROC) curve to select the optimal classification threshold that balances true positive and false positive rates.
Stakeholder Engagement

The client and data scientists closely collaborates with the fraud analysts, risk managers, IT andministratos, customer support teams, to ensure the alignment and understanding of the fraud detection system developed.
Deployment to Feedback
The final model, predictive fraud detection system is deployed in the client's company in real-time business. The clients monitor the results and provide feedback on it's effectiveness and performance. They report any false positives or false negatives encountered. Then, these are used to fine-tune the model and increase accuracy over time.
Iterative Process
Data Scientists continue to refine and fine-tune the model based on the client's feedbacks. They experiment with new features, algorithms, and parameter settings to enhance the model's predictive capabilities and adapt to evolving fraud tactics.
Improvement and Redeployment
The model is tested and validated again before being redeployed into the company business operations. Continous monitoring and evaluation is done by both sides ensuring that it remains effective and responsive to changing fraud patterns and regulatory requirements.
Source Disclosure:
In this blog post, I will be discussing key concepts from IBM Data Science Professional Certificate by IBM and Coursera*. The course provided valuable insights into different methodologies used by a data scientist and learn the stages of data science methodology,. Throughout this post, I will be referencing and building upon the ideas presented in the course. You can find more information about the course Data Science Methodology | Coursera.*




